
Level Up Your Chip Verification With Reinforcement Learning
Harnessing the Power of RL for Efficient and Effective Chip Verification

TL;DR: In this blog, we will discuss the VeRLPY framework, which uses Reinforcement learning for Chip verification using cocotb. We will explore Reinforcement learning and how it applies to Chip verification.
The purpose of this blog is to give an overview, and it is recommended to read the paper directly.
In the era of Generative AI, where AI can write, debug code. We must harness its power to reduce the chip development cycle by optimizing the verification stage, which takes around 70% time. How to optimize? There are many ways to do that; one such way is meaningful stimulus generation, which we are going to look at now.
I believe it's time for the verification folks to develop a hybrid skill set. Since we are not going to synthesis a testbench, and “verification is software” we must explore already existing software methodologies and try to implement them.
One good example is SVunit, which verifies the individual block in design or testbench via a unit test. Akin to SVunnit, we must look around, pick, and utilize the Software methodologies.
In this blog, we are going to see how Reinforcement learning helps in generating a meaningful stimulus.
Beyond Constraint Random:
Constraint Randomization is the go-to methodology for discovering a hidden bug in a complex DUT by generating a random value within a valid range(via constraints). But it costs more simulation time and “n” number of iterations to hit the sneaky bug or to achieve coverage. This is akin to closing your eyes and shooting a stone towards the tree and hoping to get a Mango(Yes!, It is Mango season in India) or two. Rather than randomly shooting in the direction of the tree with eyes closed, why can't we open our eyes, aim, and shoot?
The thing is, randomly generating a stimulus and hoping to hit the hidden bug or increase the coverage may result in spending meaningless simulation hours if the stimulus belongs to any of these categories:
Repeated generation of the same stimulus
Stimulus from incorrect Constraint range
Incorrect combination of stimuli
This may not only cost simulation time, license fees but also delay the coverage closure, which leads to bug discovery at a later stage of the chip development cycle.
With Reinforcement Learning(RL), we can open the eyes, aim, shoot, and get the Mango(s). With RL, we can generate an impactful stimulus that makes sure the simulation time is worthwhile.
NOTE: If you are new to Constraint Randomization or Coverage, check this tutorial.
What is Reinforcement Learning?
RL is a type of Machine learning where agents learns to decide by interacting with the environment. The agent evaluates the decision (action) based on the reward or Penalties.
We can easily connect the RL in a real-life scenario of us playing a Super Mario game. At the start, we don’t know the rules, we randomly move (left or right), and see what happens. If we get the coins we can see the points go up, when we hit the Goomba, mario dies. Now we know what Mario wants to do to meet the princess. Next time, when we are playing, we will know what the rewards and penalties are.
RL Term - Super Mario Example
Agent - Mario (the player)
Environment - The world of the game: platforms, enemies, coins, pipes
State - What Mario sees: his position, time left, enemies nearby
Action - Move left/right, jump, run, shoot fireball
Reward - +10 for a coin, +100 for killing a Goomba, -1 for falling into a pit

Image from VectorStock
RL wrt Design Verification
Let’s map RL terms with Chip verification.
RL Term - Chip Verification
Agent - RL algorithm generating stimulus
Environment - Design Under Test (DUT)
State - State of DUT inferred via FSM, Registers ..
Action - Input Stimulus fed into DUT
Reward - Reward based on achieving the coverage, hitting the rare event, or finding a bug
VeRLPy: The Bridge
VeRLPY is an open-source Python library designed to make RL-driven verification easier. This paper uses the following to implement the modular RL framework:
Cocotb - For Verification
Verilog - Design
OpenAI Gym - RL Framework and Algorithm
Since the verification and RL are written in Python, it will be easy for integration. This paper implemented the RL framework to verify RLE Compressor, AXI Crossbar, and made it open-source in this GitHub repo.
I will just pick one example from the paper and give an overview of it. As it goes without saying, it is recommended to read the paper directly for a deeper understanding.
RLE (Run Length Encoding) Compressor:
Design: Run Length Encoding (RLE) compressor, which is used to store sparse matrices
Challenge: Random data doesn't efficiently test sparsity patterns, or it doesn’t hit a specific scenario. Its behavior, bugs, are heavily influenced by the patterns of zeros in the input data. Randomly generating these patterns is highly inefficient if you're trying to hit a specific or less common scenario.
RL’s Role: The RL agent controls parameters like input zero probability, count_width, and sequence length.
Target: We want the RL agent to find the specific pattern of stimulus to trigger the event called “e3”, which is a rare event.
Reward: A Positive reward is generated when this e3 event is triggered.
Result: RL significantly increased occurrences of e3 61,018 times vs. 12,290 times in random.
What just happened? RL learns to prioritize count_width values like 6,7 to hit the target “e3” event.
This paper highlights that, VeRLPy framework enables RL to automatically explore and find the specific non-obvious input conditions needed to cover rare(targeted) states in design.
How it Works:
It has 3 layers:
Hardware Layer: DUT in Verilog
Cocotb Layer: Testbench in Python
RL Layer: Reinforcement Framework in Python
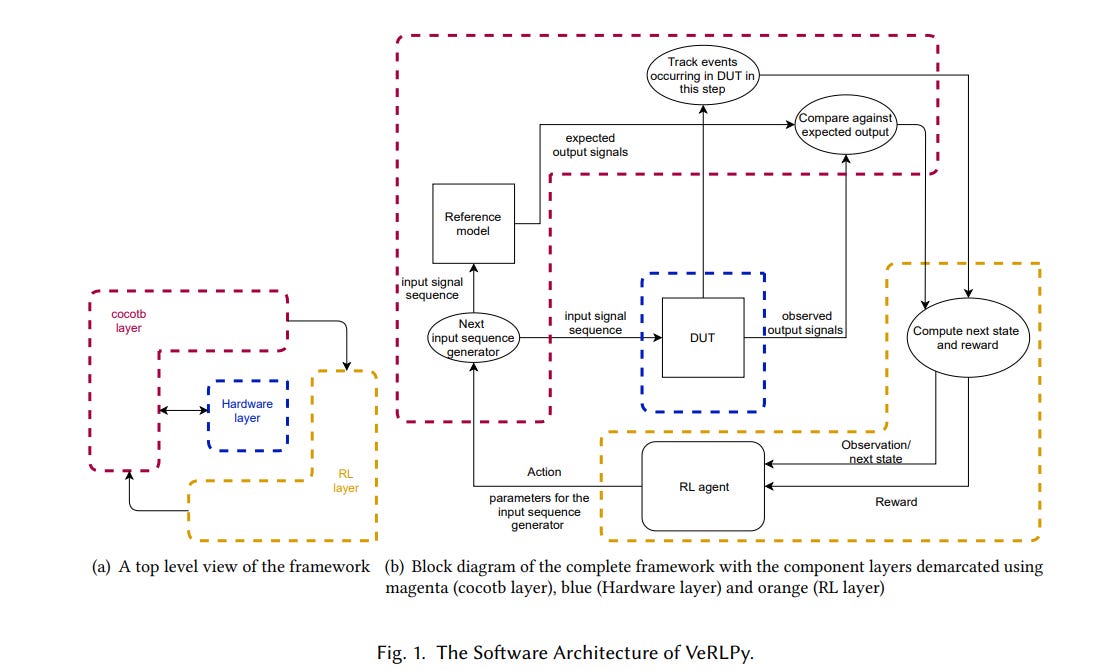
RL agent chooses an Action
Action is converted into an Input stimulus and fed into the DUT
HDL Simulator simulates with the generated input stimulus.
Cocotb monitors DUT events and internal state
RL observes DUT state/event, and calculates the reward(Positive or Negative) based on the outcome, rare event is triggered, or a coverpoint is hit or not.
Based on the reward, the RL agent updates the policy and generates a new set of values, and the loop continues.
Going Further:
Since everything is available on GitHub and we can run with the open-source tool, I would encourage everyone to give it a try and use LLM to dissect the code line by line and understand it.
Join What The Bug’s Discord Channel